Structured Analysis and Design Technique and Data Flow Diagrams
CS457 Homework #5: Robert Rice
Background
Structured Analysis and Design Technique (SADT) was developed by Douglas T. Ross in 1974. It is useful methodology for system planning, requirements analysis and system design. SADT did not evolve from a design technique, but was rather developed by examining the problems associated with defining systems requirements. It is generally not used for program design because the constructs necessary for sequence, selection and interaction are not represented within SADT. SADT should therefore be used in the planning, analysis and general design phases and other techniques should be used for detail design activities.
Representation of Components
A SADT model is graphical in order to achieve the benefits of the principles of structuring, especially top-down, levels of detail and hierarchy. Each SADT model consists of a set of related diagrams that are organized in a top-down manner. Each diagram is either a summary (parent) diagram or a detailing (child) diagram of the parent.
A SADT model is made up of two types of diagrams, an activity diagram and a data diagram. Each of these models consists of diagrams that are made up of 3 to 6 boxes and arrows. In an activity diagram the boxes correspond to activities and the arrows correspond to data. In a Data diagram the boxes correspond to data and the arrows correspond to activities. Otherwise the same syntax is used for both diagrams.
Chronological numbers, called "C-Numbers" for convenience, are used to identify unique versions of a diagram. During the development of an SADT model, a diagram with its boxes and arrows is usually redrawn several times, creating different versions of the diagram. A C-number code is constructed from the author's initials and unique sequence number. These codes are put in the lower right-hand corner of the SADT form. These C-numbers also link together diagrams in the model hierarchy. The C-Number of the diagram that decomposes a box is placed underneath that box on the parent diagram. Then that parent diagram is referenced on the decomposing child diagram.
Additionally, there are constructs that add capabilities to the language, such as the following.
- Two-way arrows to show stimulus-response.
- A scheme for explicitly assuring consistency between parent and child diagrams.
- An activation and sequencing language used to transform a functional representation into a sequence of events.
- Guidelines for writing text describing SADT diagrams.
- The capability for presenting partial diagrams for exposition of a particular aspect of a diagram.
- A series of ancillary documentation techniques, like issue sheets, schematics, and matrices.
Rules and Relationships
As mentioned above, there are two types of SADT models. An activity model is oriented toward the decomposition of activities whereas a data model is oriented toward the decomposition of data. Each type of model contains both activities and data; the difference lies in the primary focus of the decomposition.
A SADT activity describes the decomposition of activities. Data is included in the activity model as inputs, outputs, controls, and mechanisms. The top-level diagram is then decomposed and represented on separate diagrams. All data related to a given activity is explicitly shown (usually in more detail) on the lower level diagrams.
A box on an activity diagram is named with a verb or verb phrase. The left-hand side of the box is used to show input data (labeled with a noun). This is data that is to be transformed by the activity. The right-hand side of the box shows output data, which is data transformed by the activity represented by the box and is to be used elsewhere. The top of the box is used to show control data, which is data that constrains the operation of an activity. This information has two major purposes:
1. It permits the system designer to explicitly show data that is not transformed into output, but is instead used to modify the behavior of an activity.
2. It permits the designer to evaluate the cohesiveness and functional representation of all of the boxes on a diagram. Constraint relationships need to be represented in order to distinguish between the degrees of binding and to permit the designer to perform a qualitative evaluation of the decomposition.
The bottom of the box in an activity diagram is used to show a supporting mechanism of the activity. That is, if the system designer needs to describe organizations that perform a given activity, this arrow is used to identify the department, section, or even the individual responsible for the activity. The mechanism side of the box is can also be used in cross-referencing models.
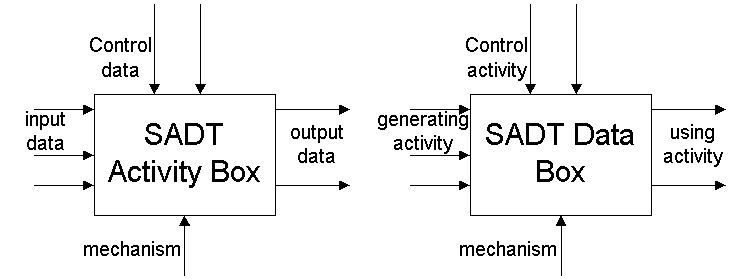
A data model is not a mirror image of the activity model, but rather is used like a data dictionary to provide a more rigorous definition of the data. The development of an activity model by itself does not provide a precise enough decomposition of data. A data diagram is created much like an activity diagram, except that the roles of activities and data are now reversed. A box on a data diagram, which is now used to represent data, is named with a noun or a noun phrase. The left-hand side of the box is used to show the activity that generates the data (an arrow labeled with a verb). The right-hand side of the box is used to show the activity which uses the data, and the top of the box is used to show the activity which constraints the generation and use of the data. Finally, the bottom of the box is used to show the storage mechanism (e.g., file) of the data. The bottom of the box, like in the activity model, can also be used to cross reference models. Images of both the data box and the activity box are shown below.
There are several layout conventions the designer can employ when creating a diagram.
- Use a waterfall pattern to emphasize dominance, minimize arrow bends and crossovers, and simplify feedback relationships.
- Place the number of each box in the lower right-hand corner. A standard location for numbers minimizes the eye movement required to locate them.
- Write the C-number of the diagram that decomposes a box below its lower right-hand corner. This minimizes eye movement, but it also visually associates a box number with the diagram that details it.
There are also conventions to consider when implementing the arrows in a diagram.
- Boxes should always have control arrows, but may or may not have input arrows. Control arrows constrain and trigger system functions. Without them, a system cannot operate.
- Draw only a control arrow when the data serves as both control and input. This reduces the complexity of the overall picture, and makes it clear that the data is for control as well as transformation.
- Join open-ended arrows when they represent the same data. This correctly shows in a graphic way that similar data comes from the same source.
There are also constraints to consider when relating boxes to arrows.
- Bundle arrows with the same source or same destination if the data is related. Doing so will yield an aggregate name that better describes the nature of the data.
- Unless the dissimilarity of data requires otherwise, minimize the number of arrows touching any one side of a box.
- Control feedback arrows are drawn "up and over" the box. This correctly shows constraint feedback with the minimum of lines and crossovers, and tends to force all control arrows into the upper right-hand region of the diagram.
- Input feedback arrows are drawn "down and under" the box. This correctly shows reverse dataflow with the minimum of line crossovers, and tends to force all input arrows into the lower left-hand region of the diagram.
- Avoid unnecessary arrow crossing when interconnecting many boxes.
Strengths
SADT
- Provides a precise method to graphically represent complex software system requirements.
Provides a clear top-down approach to decomposing the problem.
Separates data from control by separating these functional domains in the diagramming process.
Promotes teamwork and agreement on specifications before continuing design.
Requires that high level decisions must be made early, thus providing a sound basis for other decisions.
Permits non-software people to understand the requirements.
Provides an easy way to measure progress by measuring the amount of diagrams implemented at a given time.
Weaknesses
SADT
- Is not automated.
- Might cause difficulty because it is sometimes hard to think only in functional terms.
- Doesn’t support a specific design methodology.
- Takes a good deal of preparation time and might make management impatient.
- Diagrams can be difficult to understand due to the additional control information in systems where there are a lot of diagrams arranged in a hierarchical order.
Demands strict discipline between developers, making it difficult for designers working independently to show the flow of products between processes.
Example
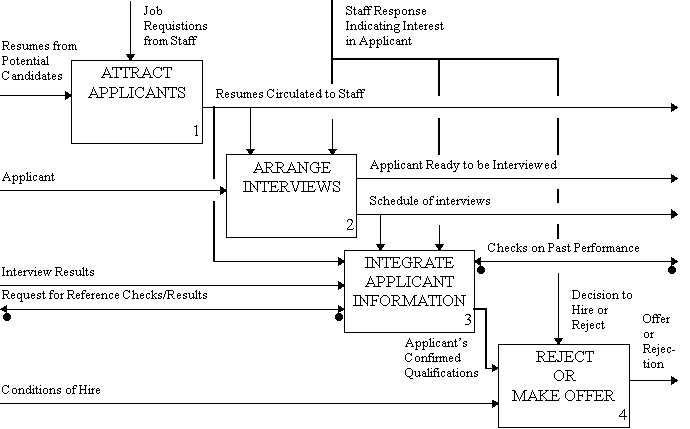
This image represents an example of a SADT activity diagram that represents a hiring process at a company.
Tools
ORCHIS is a graphical interactive environment designed for the IDEF0 method implementation. It is a collection of graphical and textual editors integrated to the windowing system. Access to commands is done by utilizing pull down and pop-up menus. The development of an application in ORCHIS is done through 3 stages:
1. Specify the system with automatic control of the syntax in the graphic editor. The designer formalizes the behavior of the hierarchical system with activity boxes connected to one another by arrows. ORCHIS also provides a label editor, a definition editor and the text editor.
2. Compare the modeled system against the IDEF-0 standard. A ‘checker’ scans the selected IDEF-0 object, evaluates the existence of inconsistencies, and displays the errors met.
3. Write the documentation. ORCHIS composes a review document with a cover page chosen by the designer. The designer also chooses in the summary the activity boxes to be printed, and selects printing of the graphic and/or textual parts.
DATA FLOW DIAGRAMS
Background
A Data Flow Diagram shows the functional relationships of the values computed by a system, including input values, output values, and internal data stores. It's a diagram showing the flow of data values from their sources in objects through processes that transform them to their destinations in other objects and how this data relates to the outside world. At their lowest level of detail, DFDs are often included in a programmer's working specification when the systems analysis is complete and the system is being programmed.
The most significant characteristics of Data Flow Diagrams are
- Graphic
- Partitioned
- Multidimensional
- Emphasize flow of data
DFD's cause the designer to present a situation from the viewpoint of the data, instead of from the viewpoint of any person or organization
The processes and data flows shown on a DFD are internal to the specified system or subsystem. Yet it is helpful to identify the external sources and destinations of data created by the system. For this purpose the square is used, which represents the immediate interface of the system with the external world. When an external source of data is also a destination for data, a loop may be used. For more complicated DFD's it is recommendable to repeat the square with its occurrence number (1/2 means first occurrence of two). In case the destination or uses of data created by the system are not known, the flow simply points outside the system. Similarly, data flows may originate from 'nowhere'.
Representation of Components
Data flow diagrams use only four symbols: the square, the rounded box or circle, the arrow and a pair or horizontal lines. These symbols are represented and defined as follows.
External Entity
Source or destination of data that is external to the system.

Process Boxes
Each process box in a DFD represents an action on data. The box might contain two labels:
- The action specifies the transformation on the data.
- The actor is a noun indicating who performs the action or where it is performed.
A process step is required for any transfer of data from or to a data store. Thus, a process box must always appear between a data store and an external user.

Data Flow Arrows
Data flow arrows link all the process boxes, external entities, and data stores in DFD's. In general, data flows should be labeled at a level of detail dependent on the available information and the purpose of the DFD. Remember that the DFD's show the only the flow of data, not materials.

Data Store Rectangles
Data stores can be manual files or computer files, but the type of file is not indicated. Because the data store is transformed when data flows into it, a simple file access is not indicated. A data store is never directly associated with unprocessed data from external sources or from other data stores; there must always be a process step in between.

Rules and Relationships
The level of detail included in a DFD depends on the purpose of the diagram. In early development process, designers abstract the system in order to concentrate on data flow, postponing the determining details until a better understanding of the system has been established.
For readability, data flow diagrams should be organized to read from left to right and top to bottom. This recommendation applies to overall organization of the diagram, not to each data transformation. One way to achieve this is to place the key external source or initial process in the top left-hand corner of the page and work down and to the right.
The data flow diagram for a complicated system may fill one or more large sheets of paper. Moreover, packing one diagram with too many details will cause confusion. To make this DFD more readable, you should use structured decomposition or leveling: the process of organizing DFD's into a hierarchy of increasingly detailed views of processes. The overview, or parent, DFD shows only the main processes. This is the level 0 diagram, also called the context diagram. It represents the entire system’s relationship to the outside world. Each parent process is composed of more detailed processes, called child processes. The most detailed processes, which cannot be subdivided any further, are known as functional primitives.
The above-mentioned rules for the DFD-construction are summarized below.
|
Overall: |
1. Know the purpose of the DFD. It determines the level of detail to be included in the diagram. |
| |
2. Organize the DFD so that the main sequence of actions reads left to right and top to bottom. |
| |
3. Very complex or detailed DFD's should be leveled. |
|
Processes: |
4. Identify all manual and computer processes (internal to the system) with rounded rectangles or circles. |
| |
5. Label each process symbol with an active verb and the data involved. |
| |
6. A process is required for all data transformations and transfers. Therefore, never connect a data store to a data source or destination or another data store with just a data flow arrow. |
| |
7. Do not indicate hardware or whether a process is manual or computerized. |
| |
8. Ignore control information (ifs, anode’s, OR’s). |
|
Data flows: |
9. Identify all data flows for each process step, except simple record retrievals. |
| |
10. Label data flows on each arrow. |
| |
11. Use data flow arrows to indicate data movement, not non-data physical transfers. |
|
Data stores: |
12. Dot not indicate file types for data stores. |
| |
13. Draw data flows into data stores only if the data store will be changed. |
|
External entities: |
14. Indicate external sources and destination of data, when known, with squares. |
| |
15. Number each occurrence of repeated external entities. |
| |
16. Do not indicate actors or places as entity squares when the process is internal to the system. |
The modeling procedure for the construction of a functional data flow model contains nine steps:
Step 1: Requirements determination
Through different techniques, the analyst has obtained all kinds of specifications in natural language. This phase never stops until the construction of the DFD is completed. This is also a recursive phase. At this moment, the designer should filter the information valuable for the construction of the data flow diagram. The different data should be ordered by:
- * Initial definition of :
- entities
- related activities
- data flows
- * Names
- * Constraints
- * Data stores
- * Incompleteness ---> Informant
Step 2: Divide activities
At this point, the different activities, their entities and their required data, should all be separated.
Step 3: Model separate activities
The activities have to be combined with the necessary entities and data stores into a model where input and output of an activity, as well the sequence of data flows can be distinguished. This phase should give a preliminary view of what data is wanted from and given to whom.
Step 4: Construct preliminary context diagram
The context diagram is very useful in identifying the different entities. It gives a steady basis in entity distinction and name giving for the rest of the construction. The designer can now apply the top-down approach and start a structured decomposition. This is the process of organizing the diagrams into a hierarchy of increasingly detailed views of processes.
Step 5: Construct preliminary level 0 diagrams
The overview, or parent, data flow diagram shows only the main process and its relation to the outside world.
Step 6: Deepen into preliminary level n diagrams
This step decomposes the level 0 diagram. Each parent process is composed of more detailed processes, called child processes. The most detailed processes, which can not be subdivided any further, are known as functional primitives. Process specifications are written for each of the functional primitives in a process.
Step 7: Combine and adjust level 0-n diagrams
During the structured decomposition, the creation of the different processes and data flows most often generate an overlap in names, data stores and others. Within this phase, the designer should coordinate the separate parent and child diagrams to each other into a standardized decomposition. The external sources and destinations for a parent should also be included for the child processes.
Step 8: Combine level 0 diagrams into definitive context diagram
The decomposition and adjustment of the leveled diagrams will most often affect the quantity and name giving of the entities. This phase will give the final form to the context diagram and the involved entities will be in their final state.
Step 9: Completion
The final stage consists of forming a structured decomposition as a whole. The input and output shown should be consistent from one level to the next.
The result of these steps, the global model, should obey all the decomposition rules.
Strengths
Data Flow Diagrams
- Describe a model more clearly and less complexly than if the model were described in words.
- Provides freedom from committing to the technical implementation too early.
- Provides further understanding of the interrelatedness of systems and subsystems.
- Can easily communicate current system knowledge to users.
- Supports analysis of a proposed system to determine if the necessary data and processes have been defined.
- Provide a pictorial, non-technical representation.
- Are easy to understand, quick to produce and easy to amend.
- Help analysts understand what is going on by tracking and documenting how the data associated with a particular process moves through the system.
- Are simple and intuitive.
Weaknesses
Data Flow Diagrams
- Leave out details of the data structures.
- Require a common format for data transfer that can be recognized by all transformations, either through having each transformation agree with its communicating transformations on the format of the data, or imposing a standard format for all data.
- Do not represent interactive systems very easily because of the need for a stream of data to be processed. While simple textual input and output can be modeled in this way, graphical user interfaces have more complex I/O formats and control which is based on events such as mouse clicks or menu selections. It is difficult to translate this into a form compatible with the DFD model.
Example
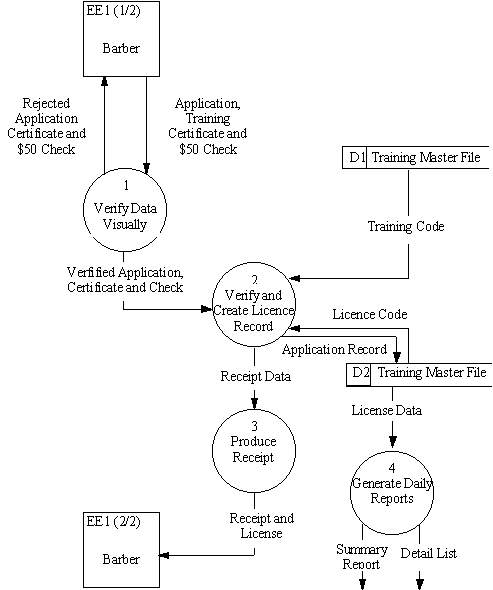
Below is an example of a high-level data diagram representing the process of training a new employee, in this case a barber.
Tools
When constructing a DFD, the use of an automated tool can be invaluable. These tools, called CASE tools (Computer Aided System Engineering), provide graphic capabilities that greatly reduce the effort required to create and modify DFDs. CASE tools have the following advantages.
- Draw and edit attractive diagrams easily .
- Automatically maintain parent/child numbering and relationships.
- Document processes, data stores, data flows and external entities .
- Automatically generate text documents.
Examples of CASE tools suitable for DFD-construction are Silverrrun-DFD, made by XA Systems Corporation and System Architecture 2001, made by Fox Data.
References
Sommerville, Ian. Software Engineering, 6th Edition. Addison-Wesley Publishers Limited. 2001.
One Tool for All Software Development. Fox Data. 2000.
http://www.business-modeling.com/english/sysarch/system_architect_modeling_tool.htm
Sonneveld, Eward. Data Flow Diagram. 1996
http://panoramix.univ-paris1.fr/CRINFO/dmrg/MEE/misop025/info.html
Connor, M.F. Structured Analysis and Design Technique, Waltham, 1980.
Marca, D.A., McGowan, C.L., Structured Analysis and Design Technique, Massachusetts, 1987.
M.J. Mulder, M.J., Koorn, M.P. Homepage About the SADT.
http://panoramix.univ-paris1.fr/CRINFO/dmrg/MEE97/misop001/index.html
Mighty_Rabit@hotmail.com